Docker Storage Driver von devicemapper auf overlay2 migriert; Discourse wies auf den fehlenden Support hin:
Your Docker installation is not using a supported storage driver. If we were to proceed you may have a broken install.
aufs is the recommended storage driver, although zfs/btrfs and overlay may work as well.
Other storage drivers are known to be problematic.
You can tell what filesystem you are using by running “docker info” and looking at the ‘Storage Driver’ line.
If you wish to continue anyway using your existing unsupported storage driver,
read the source code of launcher and figure out how to bypass this check.
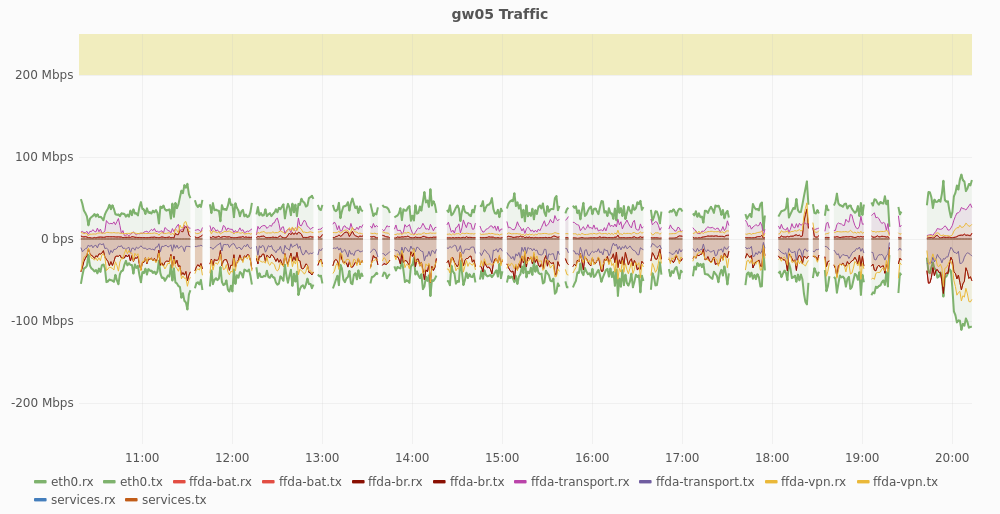
Wir stellten gerade Paketverlust von ~30% auf rumple.darmstadt.freifunk.net, einem unserer geclusterten VM-Hosts fest. Dabei wurde in regelmäßigen Abständen die NIC zurückgesetzt. Dieses Problem betrifft gw05/gw06 und besteht mindestens seit Beginn des Wochenendes und eskalierte heute sehr auffällig. Wir haben daraufhin einen Neustart der Maschine eingeleitet
Da es sich um ein VM-Cluster auf Basis von DRBD handelt musste der Partner-Node belle.darmstadt.freifunk.net ebenfalls neugestartet werden. Das führte zu einem weiteren kurzzeitigen Ausfall von gw02/gw03.
Update 0:50 Uhr:
Die Netzwerkkarte auf rumple.darmstadt.freifunk.net zeigt erneut den gleichen Defekt. Wir fahren gleich zur Colocation und tauschen die Karte aus.
Update 1:55 Uhr:
Die Netzwerkkarte wurde erfolgreich ausgetauscht, der Betrieb ist wieder hergestellt. Wir beobachten die Situation noch weiter.
Update 4:07 Uhr:
Der Server ist nicht mehr erreichbar, wir werden morgen versuchen die Ursachen und unsere Möglichkeiten zu ergründen. Bis dahin sind wir auf 400 eingehende VPN Verbindungen eingeschränkt, weshalb manche Knoten keine Verbindung zum Netz aufbauen können.
Update 17:40 Uhr:
Der Server läuft nun ohne die PCIe Netzwerkkarte und wir haben auf die internen Netzwerkinterfaces umgestellt. Wir beobachten nun die weitere Entwicklung.
Prometheus und Prometheus Alertmanager eingerichtet
Wir testen derzeit Rules und Alerting in #ffda-mon auf irc.hackint.org
ns*.darmstadt.freifunk.net
CAA Record für darmstadt.freifunk.net hinterlegt, die Zertifikatausstellung auf non-wildcard Zertifikate von Letsencrypt beschränken soll. Das bedeutet, dass wir für jede Zertifikatsausstellung die erprobten Validierungssschritte von Letsencrypt durchführen müssen.
In den letzten 48 Stunden haben wir spätabends und nachts diverse batman-adv Versionen auf ein Problem beim Fragmentieren von Paketen getestet. Das batman-adv Modul in den Versionen 2017.0 und 2016.5 (und vermutlich seit 2014.0) scheint kein ausreichendes Padding für sehr kleine Fragmente herzustellen, dadurch können Pakete als ungültig verworfen werden. Wir haben dafür einen Bugreport angelegt und wurden dabei von neoraider vom Gluon-Projekt beim Debuggen unterstützt.
Wir warten nun darauf, dass die Entwickler die Analyse des Problems abschließen und sich für eine Lösung des Problems entscheiden.
Im Master-Branch von batman-adv befindet sich derzeit bereits zufällig ein Patch der das Fragmentierungsverhalten ändert, so dass alle Fragmente in ihrer Größe balanciert werden. Das Problem konnte hiermit nicht festgestellt werden.
Es könnte hierbei zudem einen Zusammenhang mit feststeckenden Autoupdatern geben. Wir bleiben dran!
Wir haben in den letzten Tagen Probleme mit falschen ARP-Replies debuggt, weswegen Clients gelegentlich keine Gateways erreichen können. Dabei sind wir auf einen Knoten gestoßen, der laut Karte offline war, aber weiterhin unvollständig am Mesh teilgenommen hat. Daraufhin wurde der Betreiber benachrichtigt, der seinen Knoten neugestartet hat.
Diese Probleme konnten durch die Deaktivierung der Distributed ARP Table von batman-adv umschifft werden, ob sie nach Aktivierung wieder auftauchen kann zum aktuellen Zeitpunkt nicht sichergestellt werden. Wir werden hier in Zukunft weitere Versuche unternehmen das zu debuggen.
Für kommenden Freitag (19. Mai) stehen Wartungsarbeiten in der Colocation bevor, wir werden vermutlich im Laufe des Wochenendes Teile der Infrastruktur auf neuen Servern installieren. Es wird zwischenzeitlich zu Unterbrechungen kommen, wenn wir mehr wissen geben wir das hier und über Twitter/Facebook bekannt.
gw*.darmstadt.freifunk.net
fastd-exporter (https://github.com/freifunk-darmstadt/fastd-exporter) entwickelt und deployed, wir sammeln nun in Prometheus Metriken des VPN-Daemons sowie zu den darüber abgewickelten Tunnelverbindungen der Nodes. An den Alerting-Regeln arbeiten wir noch.
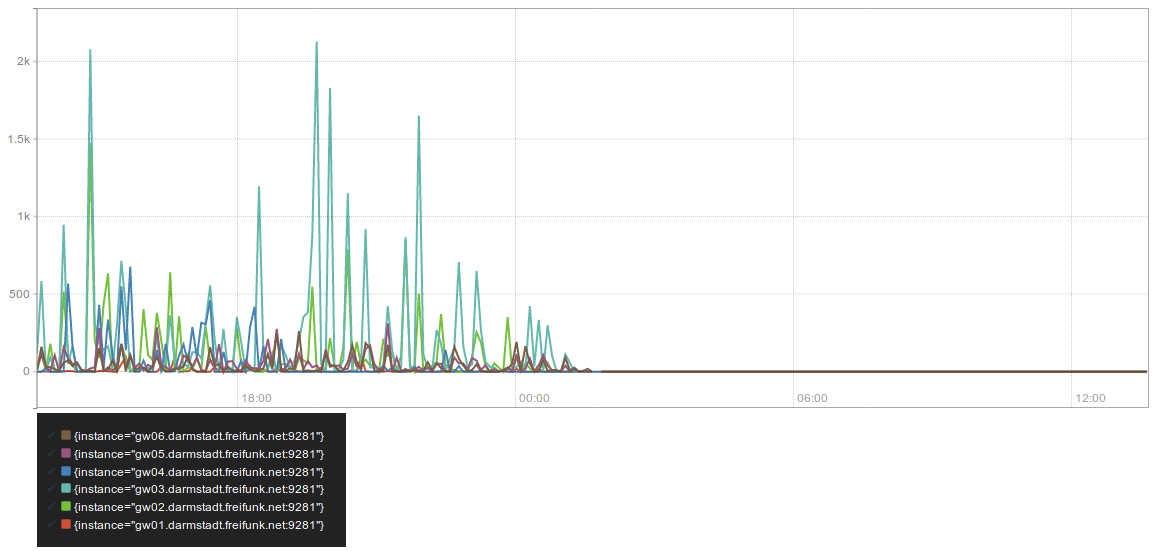
Wir hatten am vergangenen Sonntag (2017-05-28) bis in den Montag Abend hinein einen Ausfall zweier VM-Hosts zu verzeichnen. Diese hosten u.a. vier Gateways, unsere zwei Nameserver und Management-Infrastruktur. Der Grund liegt in Stromschwankungen an diesem Abend, die im Zeitraum zwischen 21:20-22:10 erfolgten. Wir konnten das Problem in den redundanten Storage-Layer (DRBD) nachvollziehen, es verhinderte, dass wir die VMs booten konnten.
Bedauerlicherweise hat sich das Problem verflüchtigt, bevor wir es endgültig identifizieren konnten. Der Backbone war somit ab Montag (2017-05-29) 20:15 Uhr wieder vollständig verfügbar.
Für Windows Clients liefern wir seit heute per Stateless DHCPv6 (RFC3736) IPv6-fähige DNS Resolver aus. Das sollte Windows-Clients durch weniger Roundtrips schneller eine funktionierende (IPv6-)Internetverbindung bescheren.
gw*.darmstadt.freifunk.net
Router Advertisments beinhalten nun das O-Flag (Other Configuration), dass Clients dazu veranlasst weitere Informationen per DHCPv6 anzufragen
DHCPv6 Server, der zustandslos Informationsanfragen nach IPv6-fähigen DNS Resolvern beantwortet
Wenn im Backbone alles ruhig verläuft, dann haben wir insgesamt weniger zu tun. Wir haben daher primär eine Änderung betreffend der VPN MTU zu verkünden, die in der aktuellen Firmware (v1.0.3, v0.9.8) bereits genutzt wird um die Fragmentierung von vollen Paketen zu verringern und somit einen besseren Datenfluss zu erzeugen.
gw*.darmstadt.freifunk.net:
batman-adv: aktualisiert auf v2017.3
fastd: neue Instanz mit 1312 Byte MTU auf Port 6101
iptables: MSS clamping um jeweils 32 Byte angehoben
Monitoring ist ein essentieller Bestandteil einer zuverlässiger Infrastruktur. Wir setzen dafür auf Prometheus, was auf sogenannten Timeseries aufbaut.